1. Introduction
Deepfake technique has ignited extensive interests in both academia and industry in recent years and inspires plenty of applications such as entertainment [1] and privacy applications [2]. It aims to swap a face of an image with someone else’s likeness in a reasonable manner.
Recent studies have shown that high-fidelity face-swapping generation is achievable [3,4,5]. By disentangling the identity information and attribute information from images, they achieve excellent performance in frame-level face swapping [6,7]. These high-quality face-swapping results are spread in social media, which causes significant malicious influences. Researches about deepfake also attract tremendous attention in the academic community [8,9,10]. However, they swap faces by simply merging different features extracted from different person frame by frame, which may lead to unnatural results.
Generating continuous face-swapping sequences is a very challenging task. Directly generating face-swapping sequences might enhance the consistency, but it is computationally infeasible in the current environment. The main issue for the face-swapping task is how do we ensure continuity in final results. We try to find a way to inherit the continuity from the origin video directly. Inspired by prior work, we observe that the structure of a generator network is sufficient to capture the low-level statistics of a natural image or video [11,12]. Based on this observation, we conjecture that the flickering artifacts in a forged video are similar to the noise in the temporal domain. We can use a neural network to inherit the continuity from the origin video.
Until now, we have decided on the starting point of this task. However, the ending point is unreliable because of the proxy’s instability, as shown in Figure 1. Directly using the previous face-swapping proxy as a reference will cause the results’ artifacts because the artifacts in the face-swapping proxy will also be inherited. To address this issue, we introduce an aleatoric uncertainty loss that can tolerate the uncertainty in proxy data during our training. Furthermore, to get higher-quality results, we introduce static 3D detail supervision for fine-grained detail reconstruction.
Figure 1. Previous methods suffers from two main problems in frame-level. First, they cannot inherit whole pose information from target image, i.e., gaze direction deviation. Besides, they cannot generate harmony results in complex environments, i.e., shadow areas.
In this paper, we propose a novel Neural Identity Carrier (NICe), which learns identity transformation from an arbitrary face-swapping proxy via a U–Net. To better model the inconsistency of face-swapping proxy, we introduce an aleatoric uncertainty loss that can tolerate the uncertainty in proxy data, and force our NICe to better learn the primary identity information in the meantime. Besides, we also introduce detail consistency transfer to guarantee the fine-grained detail information, i.e., moles and wrinkles. Extensive experiments on different types of face-swapping videos demonstrate the superiority of our method both qualitatively and quantitatively, including better retention of the attribute information from the target.
The main contributions of this paper can be summarized as follows:
We propose a novel Neural Identity Carrier (NICe), which learns identity transformation from an arbitrary face-swapping proxy via a U–Net.
To better model the inconsistency of face-swapping proxy, we borrow the theory of aleatoric uncertainty. Moreover, we introduce aleatoric uncertainty loss to tolerate the uncertainty in proxy data and force our NICe to learn the primary identity information in the meantime.
With the predicted temporally stable appearance, we further introduce static detail supervision to help NICe to generate results with more fine-grained details.
We also verify that the refined forgery data can help to improve temporal-aware deepfake detection performance.
The rest of this paper is organized as follows. Related works of face swapping approach, uncertainty modeling, and 3D face reconstruction are presented in Section 2. A detailed description of the proposed method is explained in Section 3. Section 4 demonstrates the experimental results both quantitatively and qualitatively and provides ablation study results. Section 5 presents a discussion of the proposed work, including the advantage of the framework, limitations, and broader impact. Finally, Section 6 presents a conclusion of the whole work.
2. Related Work
In this section, we review the related work from three aspects: face-swapping approaches, uncertainty modeling, and 3D face reconstruction.
2.1. Face-Swapping Approaches
Face-swapping has a long history in vision and graphic research, going back nearly two decades. They are proposed due to privacy concerns first, while they are more used for entertainment [1]. The earliest swapping methods require manual adjustment [2]. Bitouk et al. propose an automatic face-swapping method [13]. However, these methods cannot produce satisfactory results. Recently, learning-based methods have achieved better performance. Deepfakes used auto-encoder to swap faces between identity and target [14]. Ivan et al. upgraded the structure and launched an open-source project, DeepFaceLab (DFL), which is the most popular one on the Internet [15]. Nirkin et al. used a fixed 3D face shape as the proxy to increase the controllability of face-swapping [5]. Nirkin et al. proposed subject-agnostic methods which can be applied to any pair of faces without training on them [4]. And Li et al. propose a two-stage method that can achieve high fidelity and occlusion aware face-swapping [3].
Previous methods suffer from their backbone heavily. For example, auto-encoder-based methods utilize an encoder to disentangle the target person’s attribute and identity person’s identity information and reconstruct them back by a decoder—a large amount of effective information lost in the encoder-decoder process [15]. GAN-based methods cannot deal with the problem of temporal consistency and produce abnormal results occasionally [4]. In this paper, we leverage a U–Net as neural identity carrier to carry the primary information from face-swapping proxy, significantly avoiding the loss of information and producing coherent results.
2.2. Uncertainty Modeling
There are two main types of uncertainty: epistemic (uncertainty of model) and aleatoric (uncertainty of data) in deep learning fileds [16]. Thus the predictive uncertainty should consist of two parts, epistemic uncertainty and aleatoric uncertainty. As the face-swapping proxy performs severe inconsistency, the main kind of uncertainty for this issue is the aleatoric uncertainty. Further, aleatoric uncertainty also has two sub-types: homoscedastic and heteroscedastic [17].
The homoscedastic regression assumes constant observation noise σ for all input point while the heteroscedastic regression, on the other hand, assumes that observation noise can vary with input [18,19]. Especially, the heteroscedastic models are helpful when parts of the observation space might have higher noise levels than others. In previous face-swapping work, the observation noise parameter σ is often fixed as part of the model’s weight decay.
Previous methods point out that the observation noise parameter
σ can be learned as a function when data is independent [17]. Given the output, we can perform MAP inference to find a single value for the model parameters
θ:
where yi is the ground truth of the output data, f(⋅) is the model’s function, xi is the input data point, N is the number of data points, σ is the model’s observation noise parameter which captures how much noise we have in the outputs, and θ is the distribution’s parameters to be optimized.
In our work, we realize the artifacts in face-swapping proxy always occur in facial outlines and local patches. The inconsistency of face-swapping results always performs like facial outline flicker, mouth area collapse, and eye shaking. We leverage aleatoric uncertainty to predict the output’s difficult-to-generate area according to the input and reduce the weight of these areas.
2.3. 3D Face Reconstruction
3D face reconstruction has been a longstanding task in computer vision and computer graphics. It shows excellent potential in the face-swapping task. Previous face-swapping techniques tried to utilize 3DMM regression as auxiliary information to assist attribute disentanglement [20,21]. However, they only use coarse 3D reconstruction because they leverage 3D information to solve large-pose problems.
Recently, Chaudhuri et al. [22] learn the identity and expression corrective blend shapes with dynamic (expression-dependent) albedo maps. They model geometric details as part of the albedo map, and therefore, the shading of these details does not adapt to cases with varying lighting. Feng et al. propose to model facial details as geometric displacements and achieve significant improvement than previous methods [23].
Despite previous face-swapping methods utilizing 3D information to supervise their training, they only use the coarse information [4,7]. Motivated by these recent developments of 3D face reconstruction, NICe leverages the temporally stable information with static 3D detail information to build very realistic results while remedying the noise’s affecting.
3. Methods
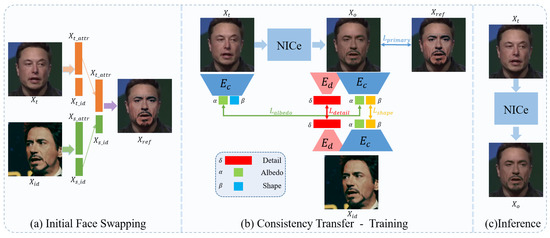
Existing face-swapping methods take identity and target image/video pairs as input. In this paper, we treat the face-swapping problem from a novel perspective. We focus on consistency inheritance in the whole process. Given an identity Xid and a target Xt, here Xid and Xt can be any portrait image or video, we first use existing face-swapping methods to generate a face-swapping proxy, denoted as Xref.
Taking Xref as references, we train a U–Net as a neural identity carrier to carry the primary information of the face-swapping proxy. During the training stage, we introduce a coarse encoder Ec and a detail encoder Ed to reconstruct a series of face parameters, including albedo coefficients α, separate linear identity shape β and detail δ, which will be used as constraints of the transfer learning to generate a photo-realistic result Xo.
3.1. Initial Face Swapping
As shown in the left of Figure 2a, current face-swapping methods can be regarded as a facial attributes disentanglement and re-combination process of identity and target portraits, in which Xid provides identity information of the identity and Xt provide attribute information of the target. We use existing face-swapping methods to generate face-swapping proxies Xref. By fusing the identity and attribute embeddings, the swapped results Xref will inherit Xid’s identity traits and have Xt’s other information. Due to the limitation of existing methods, the Xref can suffer from the problems of inconsistency and visual artifacts.
Figure 2. The pipeline of our proposed framework. In the initial face-swapping stage, the face-swapping proxy Xref is obtained by swapping the identity face Xid to the target face Xt. We utilize the NICe to extract the face-swapping proxy’s information and train the NICe under 3D supervision in the consistency transfer stage. We can directly input a target image/video for inference. This framework is efficient in producing coherent and realistic swapped results.
3.2. Consistency Transfer
After obtaining Xref as a reference, we focus on the consistency transfer. The consistency transfer consists of two parts, coherence consistency transfer—inheriting the coherence from input video and detail consistency transfer—inheriting the static detail information from identity image.
3.2.1. Coherence Consistency Transfer
As mentioned before, applying swapping algorithms independently to each frame often leads to temporal inconsistency in the generated video due to the discrete input distribution. Inspired by the DVP [12], utilizing CNN to simulate unstable processing algorithms is an efficient way to improve the temporal consistency of video produced by image algorithms. The flickering artifacts in an imperfect swapped video are similar to the noise in the temporal domain, while convolutional networks can reconstruct noise-free content before the noise. Thus we believe the temporal noise of the initial swapped video can be corrected by the re-expression of the neural identity carrier. As shown in Figure 2b, we take U–Net as a NICe to remove the flickering artifacts based on face-swapping proxy Xref. During the training stage, the neural identity carrier takes Xt as input, and generate the re-expression result Xo.
3.2.2. Detail Consistency Transfer
Prior face-swapping methods rely on heavy training on input data to synthesize realistic and abundant details, such as wrinkles and moles. But the excessive training will cause the carrier’s degradation that the U–Net will no longer learn the noise-free contents but noises themselves. Thus, the over-trained U–Net’s results are inevitably direct to the flickers, and visual artifacts appear. On the contrary, the basic facial information can not be preserved well if we train the model insufficiently. To address the problem, we propose to introduce a novel 3D representation manner to help enhance the detail information of Xo without suffering the issues brought by the excessive or insufficient training process.
According to the observation, one individual will show different details when taking different expressions and poses. The detail information of a subject is not all static. To address this issue, we suppose that the detail information should be separated into two parts, dynamic detail, which represents expression-related detail information, and static detail, which represents resident detail information. In this paper, we utilize a detail UV displacement map D to represent the details (both dynamic and static). By extracting the static detail information from identity images, NICs can learn fine-grained facial structure.
3.3. Static Detail Extractor
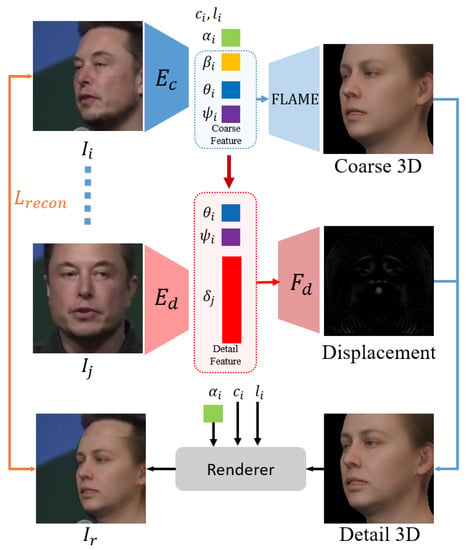
Getting a static detail extractor is not easy. First we adopt a pre-trained state-of-the-art 3D reconstruction model [23] as a coarse encoder. This coarse encoder Ec enables 3D disentanglements in FLAME’s model space [24] and regress a series of FLAME parameters, geometry parameters β, ψ and θ, albedo parameters α, camera parameters c and lighting parameters l. Among geometry parameters, β describes the shape information, ψ is the expression parameters, θ represents other coarse geometry information, such as the angle of jaw, nose, and eyeballs.
We conjecture that the dynamic detail information can be represented by the expression parameters ψ and the pose-related parameter θ. To gain an efficient static detail representation, we propose to train an extractor Ed, with the same architecture as Ec, to extract the static detail information, i.e., moles and wrinkles, from input images.
As shown in Figure 3, the extractor
Ed encodes input image
Ij into a latent code
δ which represents static detail of
Ij. Subsequently, we concatenate the latent code
δ with expression parameters
ψ and pose parameters
θ. Such a combination is finally decoded by displacement decoder
Fd to displacement
D. The process of decode detail feature can be formulated as,
where δ controls the static detail, θ and ψ both control the dynamic detail. Then, we convert D to a normal map. And By converting original geometry M and its surface normal N to UV space, denoted as Mun and Nun, we can calculate the detail geometry Md from them. We formulate this process as
Figure 3. Illustration of our 3D detail extractor’s training process. Ec is the state-of-the-art 3D reconstruction model which disentangles the input face. The disentangled face parameters are then recombined into coarse feature and detail feature respectively.
Once the detail geometry
Md obtained, the detail normal
Nd can be derived easily. Then we obtain the detail rendering result
I′r through rendering
Md with detail normal
Nd as
where R is a differentiable mesh renderer [25] and B is the shaded texture, represented in UV coordinates. The obtained detail parameters are then used to constrain the network for more realistic results.
3.4. Training Losses
In the first stage, the initial face-swapping method can be any existing method. We primarily introduce the training process of consistency transfer and static detail extractor in this section. There are two trainable parts in our framework: static detail extractor Ed and neural identity carrier U–Net. To train a high-quality carrier network, we need to train a good extractor first.
3.4.1. Static Detail Extractor Training
In Section 3.3, we introduce the pipeline of detail reconstruction. Given a set of images from one individual, the detail reconstruction is trained by minimizing
Lrecon, formally as
with photometric loss Lpho, ID-MRF loss Lmrf, soft symmetry loss Lsym, coherence loss Lchr and regularization loss Lreg.
The photometric loss Lpho computes the distance of the input image I and the rendering Ir as Lpho=∥VI⊙(I−Ir)∥. Here, VI is a binary mask generated by a face segmentation method [5] which represents the facial region, and ⊙ denotes the Hadamard product. The photometric loss Lpho can enforce more attention focused on the facial region and awareness of occlusions with the help of mask VI.
Besides, we adopt the Implicit Diversified Markov Random Fields (ID-MRF) loss for geometric details reconstruction [26]. Given two images of the same subject, the ID-MRF loss minimizes the distance between these two images on VGG19’s feature level. As the same setting as previous work [26], we compute the ID-MRF loss on layers
conv3_2 and
conv4_2 of VGG19 as
where LM(layer) denotes the VGG19’s feature-level distance between I′r and I on layer layer of VGG19.
In consideration of occlusions, we also add a soft symmetry loss to regularize the non-visible face parts. The soft symmetry loss can be formulated as
where Vuv denotes the facial mask in UV space, and Flip denotes the horizontal flip operation.
As mentioned in Section 3.2, detail information is divided into two parts, dynamic and static. We believe that replacing the static detail codes of another image of the same subject should have no effect on the final rendered image, which conforms to the logical evidence that one specific person should have his own consistent static detail code. Formally, given two images
Ii and
Ij of the same subject, the loss is defined as
where βi, θi, ψi, αi, li, and ci are the parameters of Ii, while δj is the detail code of Ij.
Finally, the detail displacements D are regularized by Lreg=∥D∥1,1 to reduce noise.
3.4.2. Neural Identity Carrier Training
Given target and reference image/video
Xt,
Xref and an identity identity image
Xid, the transfer network is trained by minimizing
To learn the process of identity transformation, a primary loss is essential. In consideration of the artifacts in face-swapping proxy, we model the uncertainty at the same time. We adjust the aleatoric uncertainty loss to fit our scenario. The primary loss is formulated as
where VGG(⋅) denotes the VGG features which consist of features from layers conv1_2, conv2_2, conv3_2, conv4_2 and conv5_2. The σ denotes the model’s noise parameter—predicting how much noise we have in the outputs. It is noteworthy that we learn the noise parameter σ implicitly from the loss function. Lprimary is a basic perceptual error between Xo and Xref. This loss can basically guarantee that the NICe can learn identity transformation from arbitrary face-swapping proxy.
To enhance the quality of simulation, we adopt 3D losses with trained static detail extractor
Ed and coarse encoder
Ec. 3D losses consist of three components, albedo loss
Lalbedo, shape loss
Lshape and detail loss
Ldetail, formulated as
In consideration of the swapping area, the skin consistency between the face and the neck can be perceived by the human vision system easily. We utilize albedo loss to improve albedo consistency between
Xo and
Xt. The albedo loss is defined as
where αXo and αXt are the albedo coefficients of Xo and Xt, encoded by Ec respectively.
The shape loss
Lshape focuses on identity preserving. Formally, we minimize
where βXo and Xid are the shape parameters of Xo and Xid encoded by Ec respectively.
The detail loss
Ldetail can greatly enhance detail information. We define it as
where δXo and δXid are detail information’s latent code of Xo and Xid encoded by Ed respectively.
4. Experiments
In this part, we compare our framework with several state-of-the-art face-swapping methods by taking them as face-swapping proxies, including FaceSwap [11], DeepFakes [14], FSGAN [4] and FaceShifter [3]. The initial swapped face videos of FSGAN are built by ourselves, while others are collected from the FF++ dataset [27].
4.1. Quantitative Evaluation
For the quantitative evaluation, we compare the temporal consistency and attribute differences among the results of ours and others. We use the stability error
estab to measure the temporal consistency:
where estab(Ot,Ot−1) measures the coherence between two adjacent output Ot and Ot−1, Mf is the facial area mask, Wtt−1(⋅) is the function to warp Ot−1 to time step t using the ground truth backward flow as defined in [28], Ot and Ot−1 are the results of frame t and t−1. Here, we only evaluate stability in facial regions. Lower stability error indicates more stable results. For the entire video, we use average errors instead. As shown in Table 1, Our method outperforms all mentioned methods which means that our method produces more steady results.
Table 1. Temporal coherence estab comparison of different face-swapping methods. DF denotes Deepfake, FS denotes FaceSwap, FSGAN denotes FSGAN, and Fshift denotes FaceShifter. Our framework can reduce the stability error of swapped results which represent better temporal coherence.
We also evaluate the attribute differences, including gaze direction, pose, 2d landmark, and 3d landmark with Openface [29]. A lower difference indicates better inheritance. As shown in Table 2, our method can inherit more attribute information than previous methods.
Table 2. Quantitative comparisons among different face-swapping methods of gaze direction, pose, 2D landmarks, and 3D landmarks. Our method apparently reduces the attribute differences which represents that our method can better inherit the attributes from the target video.
4.2. Qualitative Evaluation
For visually demonstrating the superiority of our framework in temporal consistency, we select nine continuous frames in Figure 4 for comparison. It can be observed that the results of FaceSwap are volatile due to the independent deformation for face alignment in each frame, which our framework can significantly solve. FSGAN also suffers a serious consistency problem; adjacent frames’ brightness can not maintain stability. This is mainly because that its blending network cannot capture consistent information. Therefore, the facial region becomes brighter and brighter from left to right, while our method can still get very stable results.
Figure 4. The qualitative evaluation results of our method. The results of FaceSwap are unstable and full of traces of deformation. FSGAN cannot deal with brightness well, which causes bad coherence in the temporal domain. Our method can significantly eliminate the inconsistency in the temporal domain and produce satisfactory results.
4.3. Ablation Study
In this part, we investigate the efficiency of the proposed 3D loss and visualize the corresponding results. We use FSGAN as a basic face-swapping method in this experiment. The results in Figure 5 demonstrate that adopting detail losses can significantly enhance the re-generation quality. Details become richer after adopting detail losses. More specifically, detail information, such as the eyeglasses’ shading in row 1 and wrinkles in row 2, are more abundant, which makes the results more realistic.
Figure 5. Ablation study on 3D loss. Under the constraint of 3D loss, the generated result can obtain more detail information and make results more realistic.
4.4. Ability to Improve Forgery Detection
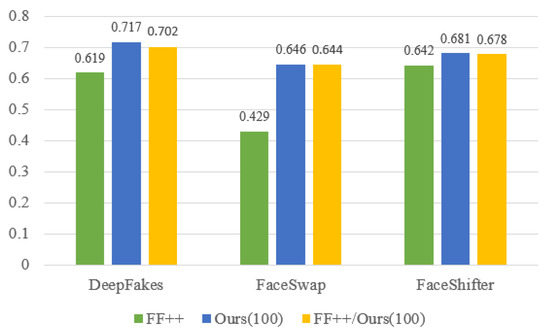
We conduct additional experiments to verify that data synthesized by our framework can help to enhance current forgery detection. We take I3D [30] as the baseline, which is the most efficient video-level forgery detection method and has a recognized generalization ability. We train the baseline on 100 videos from FF++ [27] datasets and evaluate the cross-dataset performance on CelebDF-v2 [31]. Then we utilize our framework to refine the previous 100 videos from FF++ and train I3D on them. Finally, we merge the refined videos with initial videos and train I3D on them. As shown in Figure 6, a model trained on our data can achieve better performances, which indicates that our framework has great value to enhance the current deepfake datasets.
Figure 6. The testing accuracy comparison results on CelebDF-v2 of detection models trained on different datasets. The training data generated by our method provides better temporal coherence and quality which is challenging for detection and is able to help promote the ability of detection models.
5. Discussion
In this section, we discuss the advantages and limitations of our work. Besides, we discuss the broader impact of our work which may bring severe ethical problems.
5.1. Advanced Framework
As shown in Figure 2a, most previous face-swapping methods can be regarded as the facial attributes disentanglement and re-combination between identity and target. It is noteworthy that the face reconstruction models in such methods do not play a fixed role in training and inference. They use attributes from a natural portrait image for training while using edited attributes for inference. Apparently, switching the latent codes between different subjects must have a bad effect on the final result. As shown in Figure 2b,c, unlike previous methods, our framework only takes Xt as input in both the training and inference stage. The identity information of Xid is already learned by NICe and keeps constant in the inference. Thus the final output results Xo can significantly retain more attributes of Xt, such as gaze direction.
Figure 7 gives examples of attributes preservation, here we use DeepFaceLab [15] for comparison. Although DeepFaceLab can produce high-quality swapped results with plenty of post-processing operations, it still suffers from detail inconsistency, such as gaze direction and motion blur. But our framework perfectly inherits the gaze direction and motion blur from target Xt.
Figure 7. Examples of attributes preservation. The first row shows that our method can inherit gaze direction from the target. The second row shows that our method can preserve the same motion blur as the target.
5.2. Limitations
Our framework must use the existing face-swapping method’s result as a proxy, which also brings a limitation. The face-swapping proxy limits the quality of generated results. Specifically, if the face-swapping proxy cannot provide satisfying facial content as a reference, our method cannot produce a high-fidelity face even though we introduce detail consistency as supervision.
5.3. Broader Impact
Face-swapping algorithms always face severe ethical problems. We sincerely notice the ethical problem.
Conquering the harmful effects of face-swapping algorithms needs the research of detection algorithms and the investigation of manipulation methods. However, the detection ability always depends on the generation ability. It is challenging to detect high-quality face-swapping videos because attackers can set off a public opinion storm by producing a high-quality video regardless of the costs.
As to deepfake detection, the detectors always need enormous spoofing data to build a robust detection model. Although several datasets have been proposed, there is always a lack of high-quality data. Our method can be leveraged to enhance significantly previous face-swapping methods and build more extensive datasets with coherent and high-quality results.
In the future, we’ll expand the current Deepfake dataset (synthesized by our framework) to advance state of the art in Deepfake detection algorithms. With the help of our methods, the high-quality deepfake dataset could be established with high temporal consistency deepfake content.